머신러닝을 위해 이미지를 모으는 것은 매우 단조롭고 귀찮은 일입니다. 이것을 좀더 쉽게 해봅시다.
1. Selenium 이란.
Selenium은 웹 브라우저의 자동화를 가능하게 하고 지원하는 다양한 도구와 라이브러리를 포함한 프로젝트입니다.
www.selenium.dev/documentation/ko/
Selenium 브라우저 자동화 프로젝트 :: Selenium 문서
Selenium 브라우저 자동화 프로젝트 Selenium은 웹 브라우저의 자동화를 가능하게 하고 지원하는 다양한 도구와 라이브러리를 포함한 프로젝트입니다. 브라우저와의 사용자 간의 상호 작용을 테스��
www.selenium.dev
셀레늄은 웹드라이버를 이용하여 브라우저를 열고 브라우저상의 행동을 자동으로 제어하도록 만든 엄브렐라 프로젝트의 일부입니다.
파이썬에서 자주 사용되는 beautifulsoup와 비교했을때의 차이점이 여기에 있는데. 셀레늄을 실행하면 새로운 자동화 브라우저 창이 떠오르고 미리 예정된 행동들이 수행 됩니다.
2. 준비하기
셀레늄 사용을 위해선 웹드라이버가 필요합니다. 아래 링크(셀레늄 공식 홈페이지 입니다.)에서 간단한 설명과 다운받을 수 있는 주소로 연결됩니다.
www.selenium.dev/documentation/ko/webdriver/driver_requirements/
드라이버 요구사항 :: Selenium 문서
드라이버 요구사항 Selenium은 WebDriver를 이용하여 Chrom(ium), Firefox, Internet Explorer, Opera, Safari와 같은 시장의 모든 주요 브라우저들을 지원합니다. 모든 브라우저가 원격 제어에 대한 공식적인 지원��
www.selenium.dev
웹드라이버를 다운받을땐 자신이 설치한 브라우저와 맞는 버전을 다운받아야 원활한 실행이 가능합니다.
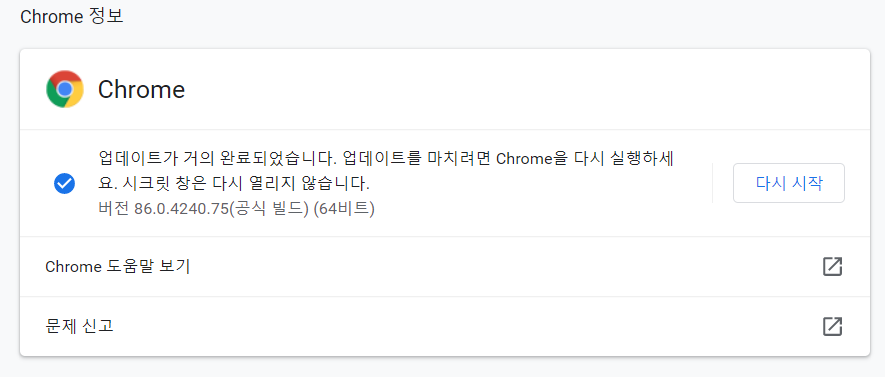
매번 최신버전으로 업데이트를 하다 보면 안될경우도 있기에 구버전을 찾아야될 경우도 있습니다.
www.slimjet.com/chrome/google-chrome-old-version.php
Download older versions of Google Chrome for Windows, Linux and Mac
Google Chrome Older Versions Download (Windows, Linux & Mac) Why use an older version of Google Chrome? Google only provides an online setup file for Google Chrome which installs the latest version of Google Chrome. It happens frequently that a user upgrad
www.slimjet.com
3. 시작하기.
위 링크의 간단한 예시를 살펴봅시다.
#Simple assignment
from selenium.webdriver import Chrome
driver = Chrome()
#Or use the context manager
from selenium.webdriver import Chrome
with Chrome() as driver:
#your code inside this indent크롬을 직접 import해서 사용하지만 크롬으로 잘 안 될 경우 브라우저를 바꿔서 진행하기에 보통 다음과 같이 import합니다.
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver = webdriver.Firefox('./geckodriver') 이 두가지를 사용해봤으며, 다른 브라우저들도 불러서 쓸수 있습니다.
괄호안의 경로는 웹드라이버 파일의 상대경로 입니다.
위의 코드를 입력하면 다음과 같이 빈화면이 실행됩니다.
4. 주소 이동
path = "https://www.google.com/search?q=" + keywords + "&newwindow=1&rlz=1C1CAFC_enKR908KR909&sxsrf=ALeKk01k_BlEDFe_0Pv51JmAEBgk0mT4SA:1600412339309&source=lnms&tbm=isch&sa=X&ved=2ahUKEwj07OnHkPLrAhUiyosBHZvSBIUQ_AUoAXoECA4QAw&biw=1536&bih=754"
driver = webdriver.Chrome('./chromedriver')
driver.get(path)
get() 안에 주소를 넣으면 해당 주소로 넘어갑니다.
아래 주소는 구글 검색후 이미지 탭을 눌렀을때 나오는 주소입니다. 검색어는 test 입니다.
www.google.com/search?q=test&newwindow=1&rlz=1C1CAFC_enKR908KR909&sxsrf=ALeKk03HZpujd4YUKSKtzoOVFh7y0Z_GnA:1603243046640&source=lnms&tbm=isch&sa=X&ved=2ahUKEwiFhKLiwcTsAhWdL6YKHe7QBv8Q_AUoAnoECAMQBA&biw=1536&bih=754
해당 부분에 검색어가 들어가며 이부분을 바꿔서 불러오면 쉽게 이미지 검색이 가능하다는 것을 알 수 있습니다.
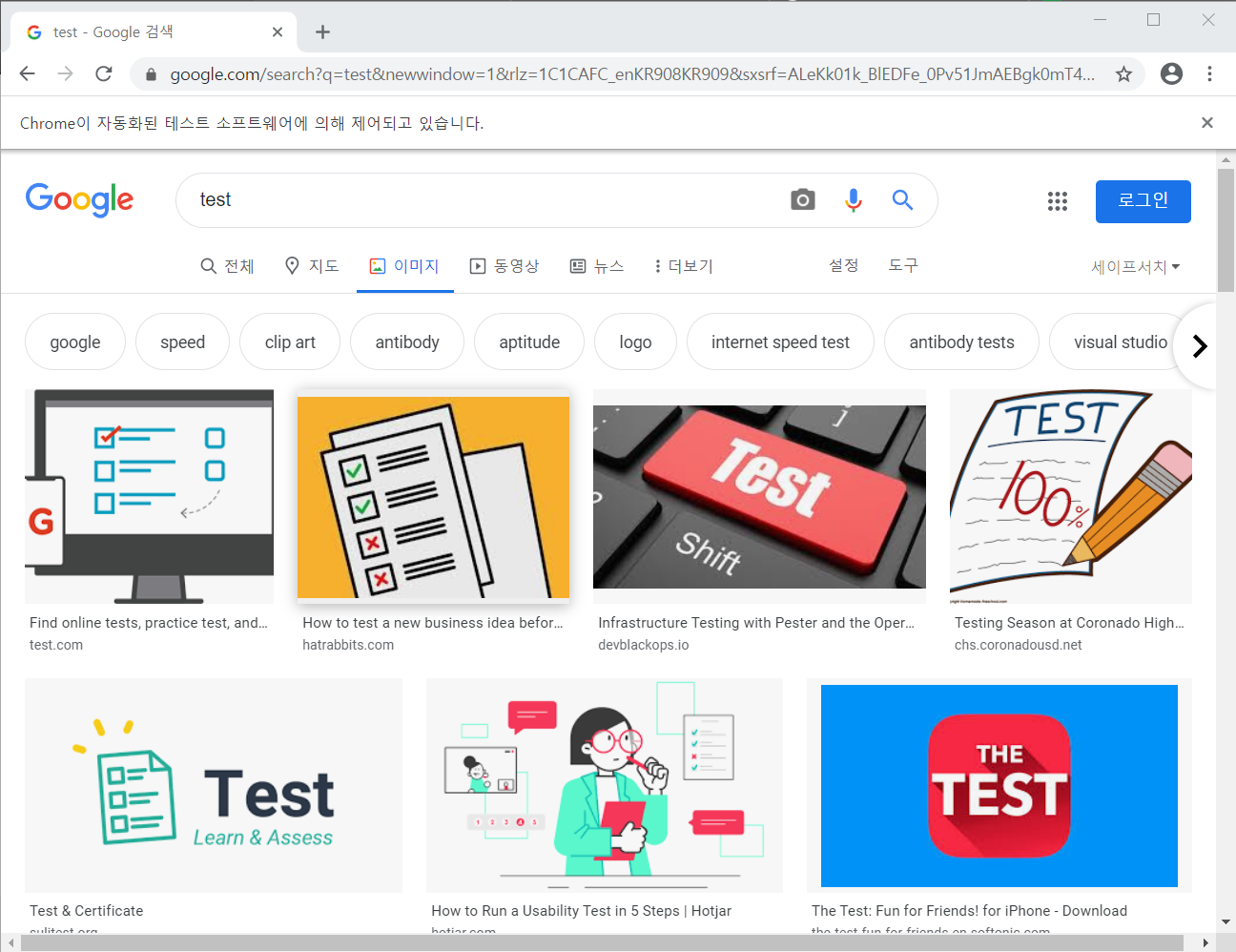
5.이미지 읽어오기
driver는 find_element 를 기본으로 Html에서 값을 읽어옵니다. 다만 그 종류가 상당히 많습니다.

기본적으론 element 라 되어있으면 최상단의 한개, elements라 되있으면 list로 묶어줍니다.
웹드라이버로 띄운 브라우저에서 f12를 누릅니다.
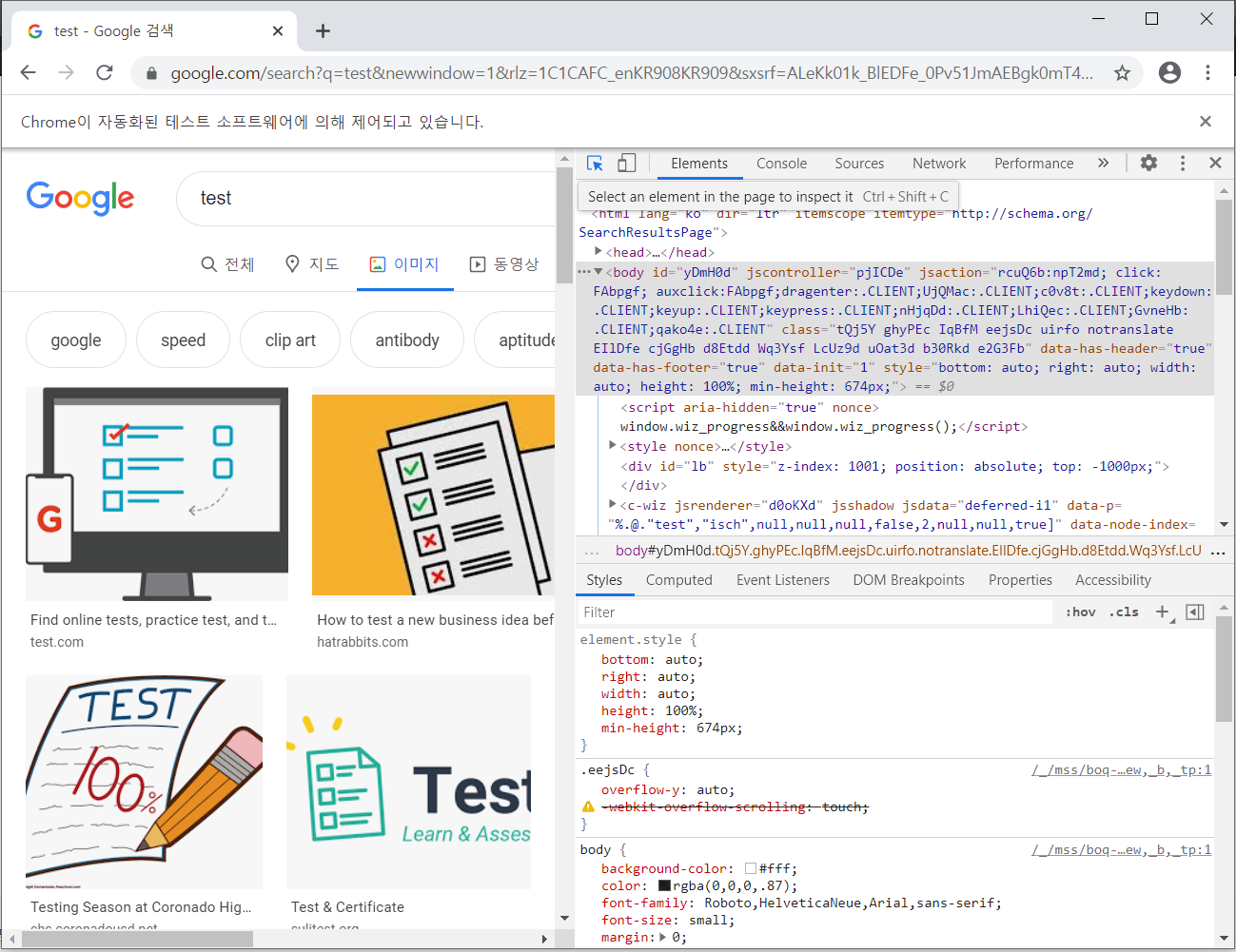
위와 같은 화면이 나오는데, 마우스 커서가 위치한 부분을 클릭하면 화면에 표시된 element들을 쉽게 확인할 수 있습니다.
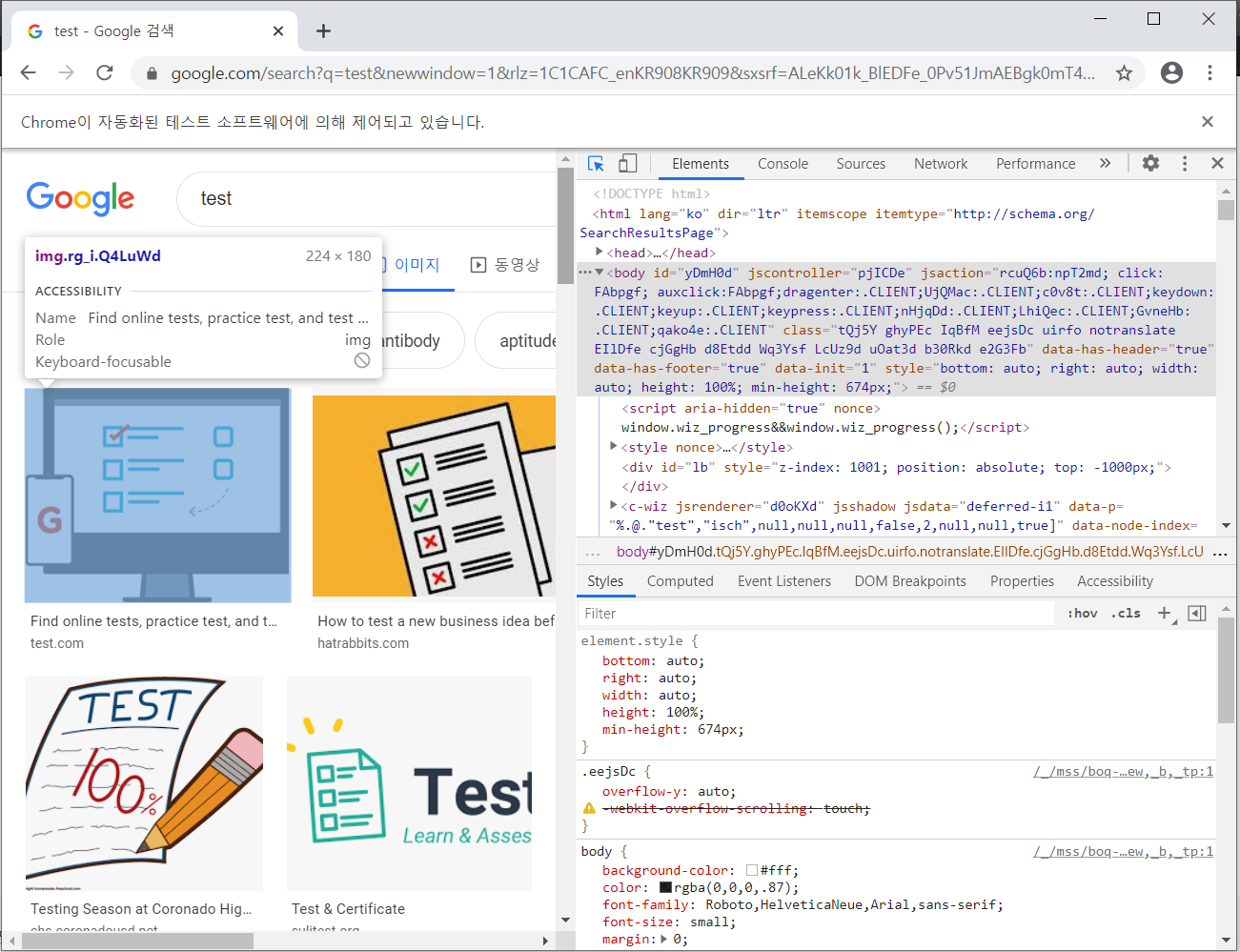
클릭할경우 오른쪽 Elements 창에서 해당부분을 찾아줍니다. 또한 우클릭을해서 해당 엘레멘트 경로를 복사하거나 할 수 있습니다.
class이름이나 tag이름으로 찾을경우 큰상관 없지만 xpath를 통해 찾을경우 xpath복사는 상당히 유용합니다.
//*[@id="islrg"]/div[1]/div[1]/a[1]/div[1]/img
이번에는 class 이름으로 이미지를 모아보겠습니다. elements창의 class안에 있는 이름을 넣고 빈공간엔 '.'을 찍습니다.
화면에 표시된 모든 이미지들을 list형식으로 찾아주고 data_src 혹은 src 안에 들어있는 이미지의 주소를 가져옵니다.
for x in driver.find_elements_by_class_name('rg_i.Q4LuWd'):
counter = counter + 1
print(counter)
# 이미지 url
img = x.get_attribute("data-src")
if img is None:
img = x.get_attribute("src")
print(img)
6. 경로 생성 및 이미지 저장.
이미지를 저장할 경로를 생성합니다.
import os
print(os.path)
if not os.path.exists('data'):
os.mkdir('data')
if not os.path.exists('data/' + keywords):
os.mkdir('data/' + keywords)
이미지를 저장합니다.
import urllib.request
# 이미지 확장자
imgtype = 'jpg'
# 구글 이미지를 읽고 저장한다.
try:
raw_img = urllib.request.urlopen(img).read()
File = open(os.path.join('data/' + keywords, keywords + "_" + str(counter) + "." + imgtype), "wb")
File.write(raw_img)
File.close()
succounter = succounter + 1
except:
print('error')
print(succounter, "succesfully downloaded")
driver.close()
urlib을 통해 이미지를 읽어오고 저장합니다.
다른 분들이 크로울링을 한 게시물을 보면 head를 넣거나 해서 봇인것을 숨기거나 하는데.. 이상하게 오류가 나서 빼버리니 잘됬습니다.
중간에 이미지 다운에 오류가 나더라도, 계속해서 진행하도록 try~except를 넣었습니다.
완료되면 다운받은 개수를 출력하고 창을 닫습니다.
7.소소한기능들
- 이미지 스크롤
구글 이미지검색의 경우 아래로 내리면 이미지가 계속해서 추가됩니다. 즉 더 많은 이미지를 원할경우 아래로 스크롤해서 이미지를 불러올 필요 있습니다.
[Python] Selenium 웹페이지 스크롤하기 scrollTo, Scroll down
Python 의 selenium 을 이용해서 스크롤 하기 크롤링 할 때 웹페이지를 스크롤 다운해야하는 경우가 있죠. 스크롤다운해서 끝까지 가야 그 다음 데이터를 조회하는 경우가 있고 그 외에도 필요한 경�
hello-bryan.tistory.com
페이지를 올리고 내리는데 정말 여러가지 방법이 많습니다. 위글의 설명을 참고하시면 보다 많은 이미지를 가져 올 수 있습니다.
- 최대화
반응형 웹사이트 특성상 브라우저의 크기에 따라 이미지를 불러오는 개수가 달라질 것입니다. 다음코드를 통해 창을 최대화 할 수 있습니다.
driver.maximize_window()
이외에도 사용할만한 method 들은 다음 link에서 확인해 볼 수 있습니다.
www.geeksforgeeks.org/web-driver-methods-in-selenium-python/
Web Driver Methods in Selenium Python - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
- tor브라우저를 통한 ip 우회
blog.naver.com/PostView.nhn?blogId=zzz90zzz&logNo=222026663292
Tor browser 로 selenium webdriver 크롤링 ip 우회 [Windosws]
그냥 tor brower 실행 후 이거 실행하면 된다톨브라우저는 여기서 깔면된다 https://www.torproject.or...
blog.naver.com
8. 사용하기 좋도록 만들기.
keyword를 보고 눈치채신 분들도 있겠지만 함수형태로 만들어서 호출해서 쓰면 편합니다.
전체코드는 다음과 같습니다.
from selenium import webdriver
import os
import urllib.request
import time
import datetime
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--proxy-server=socks5://127.0.0.1:9150")
def doScrollDown(whileSeconds, driver):
start = datetime.datetime.now()
end = start + datetime.timedelta(seconds=whileSeconds)
while True:
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(1)
if datetime.datetime.now() > end:
break
header_n = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
def crawl(keywords):
path = "https://www.google.com/search?q=" + keywords + "&newwindow=1&rlz=1C1CAFC_enKR908KR909&sxsrf=ALeKk01k_BlEDFe_0Pv51JmAEBgk0mT4SA:1600412339309&source=lnms&tbm=isch&sa=X&ved=2ahUKEwj07OnHkPLrAhUiyosBHZvSBIUQ_AUoAXoECA4QAw&biw=1536&bih=754"
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get(path)
driver.maximize_window()
time.sleep(1)
counter = 0
succounter = 0
print(os.path)
if not os.path.exists('data'):
os.mkdir('data')
if not os.path.exists('data/' + keywords):
os.mkdir('data/' + keywords)
for x in driver.find_elements_by_class_name('rg_i.Q4LuWd'):
counter = counter + 1
print(counter)
# 이미지 url
img = x.get_attribute("data-src")
if img is None:
img = x.get_attribute("src")
print(img)
# 이미지 확장자
imgtype = 'jpg'
# 구글 이미지를 읽고 저장한다.
try:
raw_img = urllib.request.urlopen(img).read()
File = open(os.path.join('data/' + keywords, keywords + "_" + str(counter) + "." + imgtype), "wb")
File.write(raw_img)
File.close()
succounter = succounter + 1
except:
print('error')
print(succounter, "succesfully downloaded")
driver.close()
crawl("test")
crawl() 괄호 안에 keyword를 입력하면 data 폴더 안쪽의 keyword폴더를 만들고 이미지를 저장합니다.
Ref)
(Crawler) selenium으로 이미지 크롤링
Selenium을 사용하여 Google 이미지에서 사람(person) 이미지를 가져오는 crawler를 만들어 보겠습니다. crawler는 python3를 사용하여 제작했습니다. 소스코드 대한 정보는 아래 블로그를 참조했습니다. http
j-remind.tistory.com
blog.naver.com/PostView.nhn?blogId=zzz90zzz&logNo=222026663292
Tor browser 로 selenium webdriver 크롤링 ip 우회 [Windosws]
그냥 tor brower 실행 후 이거 실행하면 된다톨브라우저는 여기서 깔면된다 https://www.torproject.or...
blog.naver.com
[Python] Selenium 웹페이지 스크롤하기 scrollTo, Scroll down
Python 의 selenium 을 이용해서 스크롤 하기 크롤링 할 때 웹페이지를 스크롤 다운해야하는 경우가 있죠. 스크롤다운해서 끝까지 가야 그 다음 데이터를 조회하는 경우가 있고 그 외에도 필요한 경�
hello-bryan.tistory.com
'Back > Python' 카테고리의 다른 글
| [Python] Flask를 이용한 Tflite Imageclassfier REST API 구성 (0) | 2020.11.02 |
|---|---|
| [Python][Anaconda3] Anaconda 설치(1) (0) | 2020.10.27 |
| [Python] Flask 살펴보기 (0) | 2020.10.21 |
| [Python] CSV 파일 읽기, 이미지 정리. (2) | 2020.10.06 |
| [Python] dlib 설치하기. (0) | 2020.09.01 |



