이전글에서 이어집니다.
이전 1번 글에서 밝혔듯 외국인 분이 만들어준 모델은 상당히 성능이 좋습니다.
이 모델을 적당히 수정해서 사용해 보도록 하겠습니다.
들어가기전 CNN 모델의 성능을 높이는 법에는 3가지 방법이 있습니다.

- 채널 늘리기
- 레이어 늘리기
- 원본 해상도 높이기
해당 논문에선 이 세가지 방법을 이용해서 성능을 개선한 Efficient model을 만들었다고 합니다.
더 자세한 정보

동일 논문에서 밝힌 바로는 같은 모델에서도 입력 이미지의 해상도가 높을 경우 더 높은 성능 증가율을 보여줍니다.
다만 여기서 성능이라 함은 예측성능을 의미합니다. 더 정확한 예측이 가능하다는 뜻입니다. 즉 무턱대고 이미지의 해상도를 늘리면 아주큰 난관에 걸리는데
소요시간이 어마어마하게 증가합니다. 특별히 머신러닝을 위해 맞춘 고급 컴퓨터가 아니라면 작은 이미지만, 그리고 이미지 또한 성능에 문제 없다면 가능한 작은 것을 쓰는게 좋습니다.
3-3 모델 수정, 제작
from keras import backend as K
from keras import layers as L
from keras.models import Model
from keras.regularizers import l2
from keras.callbacks import ModelCheckpoint,ReduceLROnPlateau,EarlyStopping
임포트한 라이브러리는 그대로 입니다.
def Make_model(train,val):
K.clear_session()
model_ckpt = ModelCheckpoint('BrailleNet.h5',save_best_only=True)
reduce_lr = ReduceLROnPlateau(patience=8,verbose=1)
early_stop = EarlyStopping(patience=20,verbose=2)
entry = L.Input(shape=(36,36,3))
x = L.SeparableConv2D(64,(3,3),activation='relu',padding ='same')(entry)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(128,(3,3),activation='relu',padding ='same')(x)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(256,(2,2),activation='relu',padding ='same')(x)
x = L.GlobalMaxPooling2D()(x)
x = L.Dense(256)(x)
x = L.LeakyReLU()(x)
x = L.Dense(64,kernel_regularizer=l2(2e-4))(x)
x = L.LeakyReLU()(x)
x = L.Dense(27,activation='softmax')(x)
model = Model(entry,x)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit_generator(train,validation_data=val,epochs=666,
callbacks=[model_ckpt,reduce_lr,early_stop],verbose=0)
return history
다른 부분처럼 함수형태로 만들어 필요할 때 호출하도록 하였습니다.
달라진 부분을 짚어보면 우선 콜백 함수중 EarlyStopping의 patience 값을 늘렸습니다. 또한 이미지의 해상도를 28에서 36으로 올렸습니다.
입력해상도를 올리면 acc가 상당히 느리게 올라갑니다. 즉, 학습에 어려움이 생기고 학습이 오래 걸립니다.
반대로 줄이면 acc가 빠르게 올라갑니다.
비교
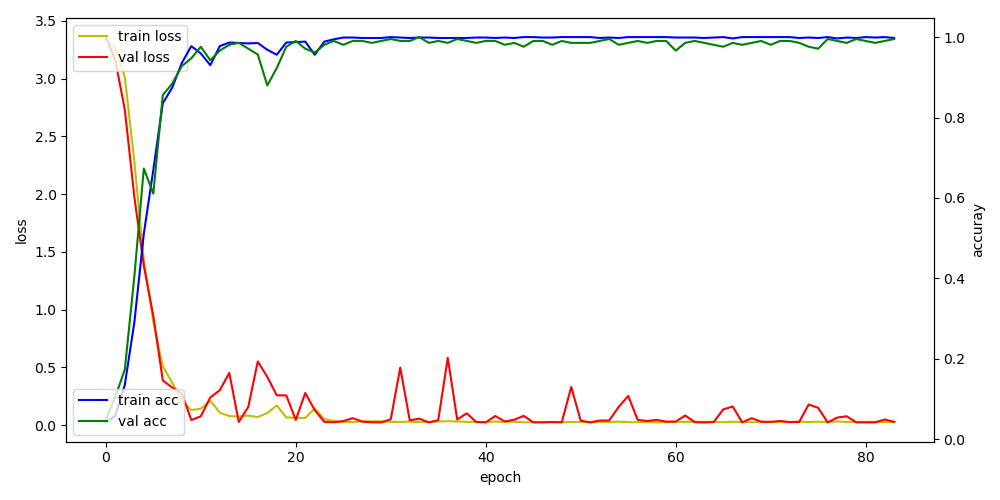
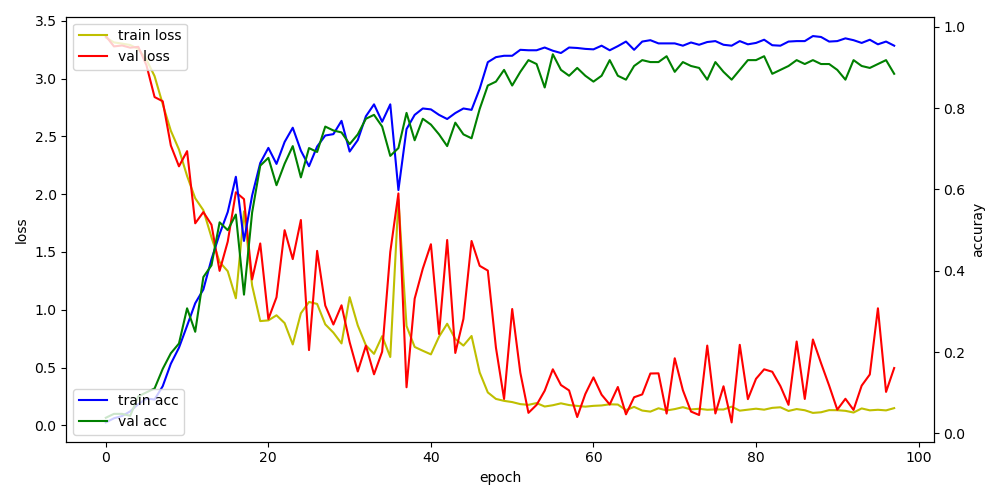
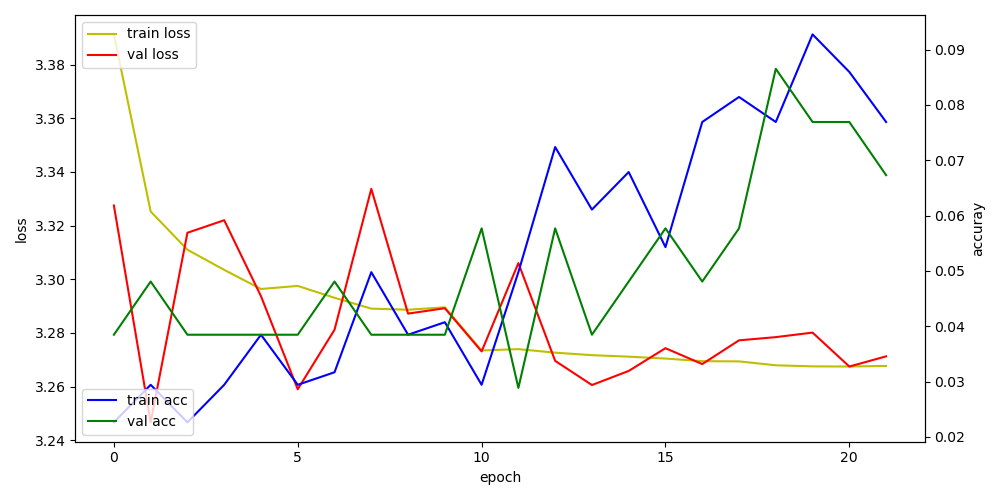
입력 이미지에 따른 acc loss 변화.
위 그래프를 그리는 함수는 바로 다음에 나옵니다.
지금 가정되어 있는 상황은 다양한 점자이미지를 받아들여(준비가 안됬지만) 분석을 해야하기 때문에 해상도를 키우는 쪽으로 정했지만 실제 검증용으로 사용되는 이미지는 깔끔하게 정돈된 이미지를 사용하기에 극단적으론 12*12 해상도를 사용해도 가능합니다.

위쪽의 이미지가 원본k이고 아래의 이미지가 12픽셀로 줄인 k입니다. 해상도를 줄여 손실되어도 구분가능하다면(성능이 같다면) 최대한 작게 쓰는것이 속도에 도움이 됩니다.
-- 9/11 추가 내용--
CNN 에서 필터의 크기는 상당히 중요합니다. 어떤 식으로 필터를 사용할지에 따라서 정확도가 달라집니다.
위에서 언급한 이미지의 해상도에 따른 처리속도, 학습정도의 차이또한 필터의 크기차이에서 옵니다.
entry = L.Input(shape=(36,36,3))
x = L.SeparableConv2D(64,(3,3),activation='relu',padding ='same')(entry)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(128,(3,3),activation='relu',padding ='same')(x)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(256,(2,2),activation='relu',padding ='same')(x)
x = L.GlobalMaxPooling2D()(x)CNN 레이어를 조금씩 뜯어봅시다. 36*36*3은 이미지의 가로 세로비와 채널의 수를 나타냅니다.
가로 36, 세로36, RGB(3)값입니다. 이를 Conv2D를 이용하여 64개의 커널을 사용해서 찾아내며 그 크기(strid)는 3*3입니다.
3*3 사이즈는 가장 흔히 사용되는 사이즈입니다만, 이미지의 해상도를 높일 경우 이미지의 정보를 제대로 담았다 보기 어려울 것이며 이는 학습에 어려움으로 나타날 것입니다.


위 두사진 안의 빨간 사각형 안부분(선의 굵기는 제외입니다.)은 3*3으로 같은 크기입니다. 위의 경우처럼 실제 이미지에서 정보가 담긴 크기가 strid보다 훨씬 크다면 같이
키워 주는 것이 좋습니다.
아래와 같이 모델 구조를 바꿔보았습니다.
def Make_model(train,val):
K.clear_session()
model_ckpt = ModelCheckpoint('BrailleNet.h5',save_best_only=True)
reduce_lr = ReduceLROnPlateau(patience=8,verbose=1)
early_stop = EarlyStopping(patience=5,verbose=2,monitor='accuracy')
entry = L.Input(shape=(50,50,3))
x = L.SeparableConv2D(128, (10,10), activation='relu', padding='same')(entry)
x = L.MaxPooling2D((2, 2))(x)
x = L.SeparableConv2D(256,(10,10),activation='relu',padding ='same')(x)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(512,(10,10),activation='relu',padding ='same')(x)
x = L.GlobalMaxPooling2D()(x)
x = L.Dense(512)(x)
x = L.LeakyReLU()(x)
x = L.Dense(256)(x)
x = L.ReLU()(x)
x = L.Dense(128,kernel_regularizer=l2(2e-4))(x)
x = L.ReLU()(x)
x = L.Dense(27,activation='softmax')(x)
model = Model(entry,x)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit_generator(train,validation_data=val,epochs=60,
callbacks=[model_ckpt,reduce_lr,early_stop],verbose=2)
return history
이미지의 해상도를 50*50으로 변경하고 필터의 크기를 10*10으로 변경했습니다.
학습 그래프는 아래와 같습니다.

학습속도는 물론이고 정확도 역시 크게 향상되었습니다. CNN의 경우 그림의 종류에 따라 값이 달라지지만 아주 많이 정제된 테스트 파일과 검증 자료 그리고 특징의 크기가 비슷비슷한 점자의 특징 덕분에 이런 결과가 나온것 같습니다.
더불어 이미지의 크기와 필터의 크기를 대략 나타내면 이렇습니다.

이후 history를 return받아 acc와 loss의 변화를 눈으로 확인할 수 있게 도식화 하였습니다.
def print_acc_loss(history):
# 평가 결과 도식화
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots(figsize=(10, 5))
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r', label='val loss')
acc_ax.plot(history.history['accuracy'], 'b', label='train acc')
acc_ax.plot(history.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
이하 코드 전문
from keras import backend as K
from keras import layers as L
from keras.models import Model
from keras.regularizers import l2
from keras.callbacks import ModelCheckpoint,ReduceLROnPlateau,EarlyStopping
def Make_model(train,val):
K.clear_session()
model_ckpt = ModelCheckpoint('BrailleNet.h5',save_best_only=True)
reduce_lr = ReduceLROnPlateau(patience=8,verbose=1)
early_stop = EarlyStopping(patience=20,verbose=2)
entry = L.Input(shape=(36,36,3))
x = L.SeparableConv2D(64,(3,3),activation='relu',padding ='same')(entry)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(128,(3,3),activation='relu',padding ='same')(x)
x = L.MaxPooling2D((2,2))(x)
x = L.SeparableConv2D(256,(2,2),activation='relu',padding ='same')(x)
x = L.GlobalMaxPooling2D()(x)
x = L.Dense(256)(x)
x = L.LeakyReLU()(x)
x = L.Dense(64,kernel_regularizer=l2(2e-4))(x)
x = L.LeakyReLU()(x)
x = L.Dense(27,activation='softmax')(x)
model = Model(entry,x)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit_generator(train,validation_data=val,epochs=666,
callbacks=[model_ckpt,reduce_lr,early_stop],verbose=0)
return history
def print_acc_loss(history):
# 평가 결과 도식화
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots(figsize=(10, 5))
acc_ax = loss_ax.twinx()
loss_ax.plot(history.history['loss'], 'y', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r', label='val loss')
acc_ax.plot(history.history['accuracy'], 'b', label='train acc')
acc_ax.plot(history.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuray')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()'Back > Deep Learning' 카테고리의 다른 글
| [Python] [CNN]점자번역 프로그램(6) (0) | 2020.09.02 |
|---|---|
| [Python] [CNN]점자번역 프로그램(5) (0) | 2020.09.02 |
| [Python] [CNN]점자번역 프로그램(3) (0) | 2020.09.02 |
| [Python] [CNN]점자번역 프로그램(2) (5) | 2020.09.02 |
| [Python] [CNN]점자번역 프로그램(1) (0) | 2020.09.02 |


